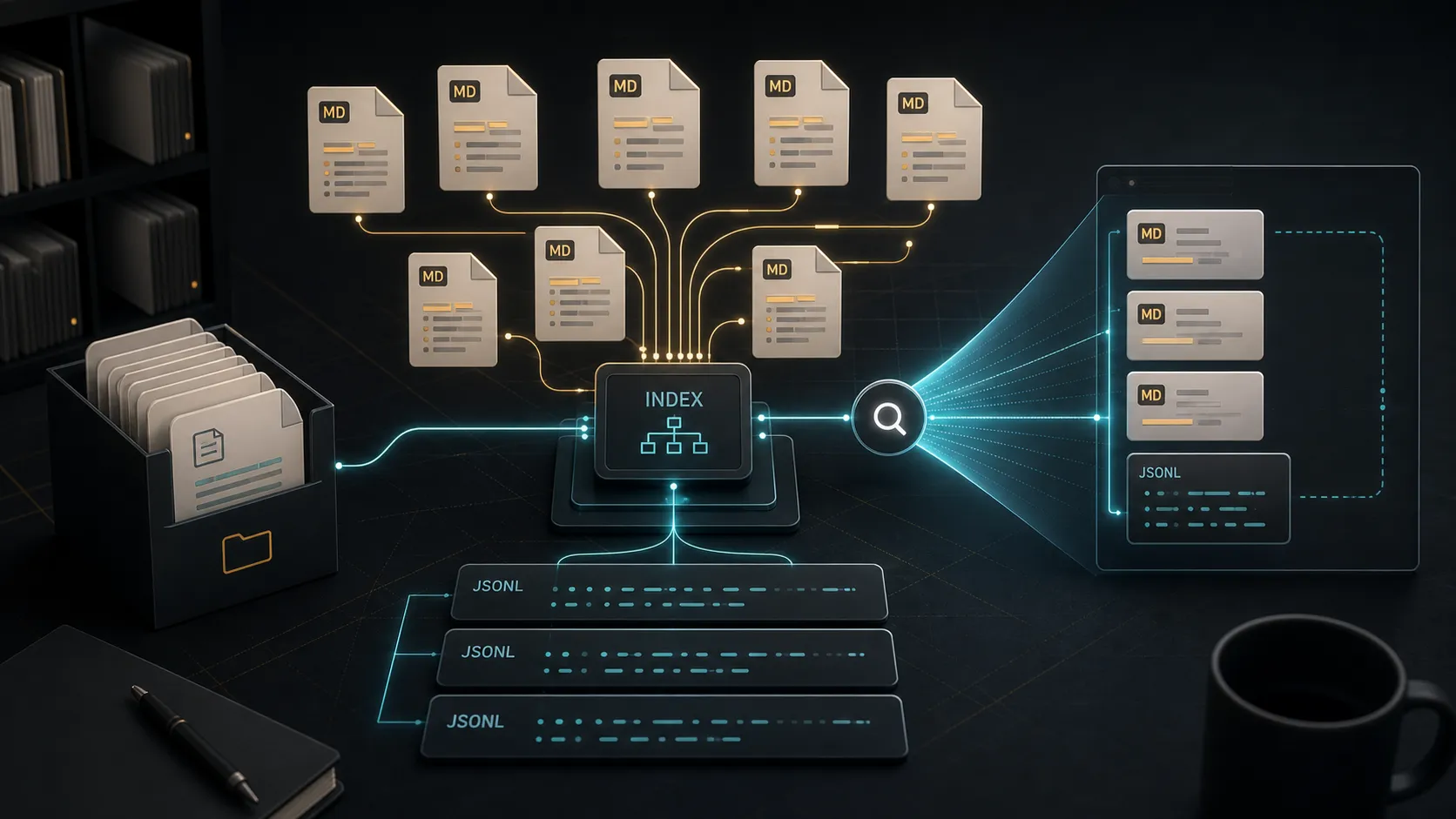
记录一次对 Codex 记忆功能的实际拆解。它不是把信息写进模型参数,也不是一个必须依赖远程数据库的黑盒系统,而是用本地文件保存摘要、索引和历史会话路径,再在需要时按关键词检索和注入上下文。
一、记忆不是模型权重
Codex 记忆,更接近一套本地 knowledge base:
/Users/<user>/.codex/memories/
├── MEMORY.md
├── memory_summary.md
├── raw_memories.md
├── rollout_summaries/
└── extensions/这说明它的工作方式不是“模型永久记住了某句话”,而是:
- 历史会话被保存在本地 JSONL 文件中。
- 有价值的会话会被压缩成 Markdown 摘要。
- 摘要再被登记到一个主索引里。
- 新任务开始时,Agent 先读摘要或索引,判断是否需要复用旧信息。
- 如果需要精确证据,再回到原始 rollout 文件里查。
所以它更像“本地文件检索 + 摘要注入”,而不是长期记忆。
二、文件结构:哪些文件负责什么
实际结构可以拆成四类。
| 文件或目录 | 作用 |
|---|---|
memory_summary.md | 全局压缩摘要,适合在新会话里快速提供用户偏好、项目历史和常见规则 |
MEMORY.md | 主索引,按任务组记录关键词、适用路径、摘要文件和原始会话路径 |
raw_memories.md | 更原始的记忆材料,通常不作为第一入口 |
rollout_summaries/ | 单次或一组会话的 Markdown 摘要 |
extensions/ad_hoc/ | 用户显式要求追加记忆时,用于放置增量说明 |
这里最重要的是 MEMORY.md 和 rollout_summaries/。
MEMORY.md 负责回答“有没有相关记忆、应该去哪看”。它不是完整历史,而是索引。
rollout_summaries/ 负责回答“上次到底发生了什么、形成了什么偏好或结论”。它不是逐字聊天记录,而是压缩后的经验摘要。
三、主索引:为什么先查 MEMORY.md
MEMORY.md 的组织方式通常是 task group。一个任务组里会包含:
scope: ...
applies_to: ...
## Task 1: ...
### rollout_summary_files
- rollout_summaries/xxx.md
(cwd=..., rollout_path=..., updated_at=..., thread_id=..., success)
### keywords
- keyword-a, keyword-b, path-a, file-a
## User preferences
- when ...
## Reusable knowledge
- ...这种格式的好处是检索成本低。
例如 codex 要处理我的博客仓库,就不用扫描所有历史会话。只需要用路径或关键词查:
rg -n "src/data/blog|Astro|博客" ~/.codex/memories/MEMORY.md如果命中 /Users/<user>/blog 对应的任务组,就能看到:
- 之前哪些博客文章被修改过。
- 文章一般放在哪个目录。
- 校验命令是什么。
- 哪些 warning 是历史已有,不应该误判成本次修改。
- 哪个
rollout_summaries/*.md记录了更多上下文。
这比直接把全部历史塞进上下文更稳定,也更省 token。
四、摘要文件:一次会话如何变成可复用经验
rollout_summaries/ 里的文件是更具体的历史记录。一个典型摘要会包含:
thread_id: ...
updated_at: ...
rollout_path: /Users/<user>/.codex/sessions/.../rollout-xxx.jsonl
cwd: ...
# 本次会话的一句话总结
Rollout context: ...
## Task 1: ...
Outcome: success
Preference signals:
- ...
Key steps:
- ...
Failures and how to do differently:
- ...
Reusable knowledge:
- ...这类文件的重点不是复盘所有聊天内容,而是提炼未来有用的信息。
这就是记忆真正有价值的地方:不是记住一句话,而是把一次纠正转成以后可执行的行为规则。
五、原始会话:什么时候才需要查 JSONL
摘要文件里通常会保留 rollout_path:
rollout_path: /Users/<user>/.codex/sessions/2026/05/20/rollout-xxx.jsonl这些 JSONL 文件才是更接近原始会话的数据。里面可能包含:
- 用户消息。
- Agent 回复。
- 工具调用。
- 命令输出。
- 中间状态。
- 任务边界。
但日常不会一上来就读它们。原因很直接:
- 原始会话太长。
- 很多细节对当前任务没有价值。
- 直接读全量历史容易引入过期信息。
- 摘要已经足够覆盖大多数复用场景。
只有在需要精确还原命令、错误文本、文件路径、测试结果时,才应该从摘要跳回 JSONL。
六、一次实际检索流程
比较合理的记忆检索流程可以写成下面这样:
用户请求
↓
判断是否需要记忆
↓
读取当前会话注入的 memory_summary.md
↓
用路径、项目名、文件名、关键词搜索 MEMORY.md
↓
打开 1-2 个最相关的 rollout_summaries/*.md
↓
必要时追溯 rollout_path 指向的 JSONL
↓
把低漂移结论用于当前任务对应到命令,大概是:
# 1. 先查主索引
rg -n "关键词|项目路径|文件名" ~/.codex/memories/MEMORY.md
# 2. 打开命中的摘要文件
sed -n '1,120p' ~/.codex/memories/rollout_summaries/<summary>.md
# 3. 如果需要原始证据,再查 rollout_path
rg -n "错误文本|命令|文件名" ~/.codex/sessions/.../rollout-xxx.jsonl这个流程里有一个关键判断:不是所有任务都需要记忆。
如果只是问当前时间、翻译一句话、解释一个独立概念,就没必要读历史。
如果任务涉及某个长期项目、全局配置、简历写法、博客风格、用户偏好,就应该查。
七、为什么不用全量自动记忆
全量自动记忆看起来省事,但实际风险很高。
第一,历史信息会过期。
比如某个仓库以前用 pnpm astro check 校验,不代表现在依赖、schema、构建命令都没变。记忆可以提示方向,但当前事实仍然要用真实文件验证。
第二,历史信息有作用域。
某个项目里的偏好,不一定适用于另一个项目。比如“只写计划不实现”可能只对应某次用户明确说了“暂不执行”,不能扩展成所有任务都不执行。
第三,历史信息可能是纠错后的结论。
如果只记住中间操作,而不记住用户纠正,就会复用错误。好的摘要应该保留“哪里做错了、以后怎么改”,而不是只保留最终结果。
所以更好的策略是:
| 信息类型 | 是否适合复用 | 是否需要重新验证 |
|---|---|---|
| 用户长期偏好 | 适合 | 低频验证 |
| 项目目录和历史决策 | 适合 | 需要按当前仓库确认 |
| 依赖版本和命令输出 | 谨慎复用 | 应该重新跑 |
| 线上状态、价格、规则 | 不应只靠记忆 | 必须重新查 |
| 用户临时指令 | 只在对应上下文内复用 | 不应泛化 |
八、如何追加记忆
从当前规则看,记忆不能由 Agent 随便写入。只有用户明确要求更新记忆时,才应该新增说明。
增量文件放在:
~/.codex/memories/extensions/ad_hoc/notes/文件名一般可以是:
<timestamp>-<short-slug>.md这里的设计很保守:不要直接改主索引,也不要让一次会话随意污染长期记忆。先把新增或修正内容作为 ad hoc note 放进去,再由后续的记忆整理流程吸收。
这能避免一个常见问题:Agent 把一次临时偏好误写成长期规则。
九、局限和边界
这套机制有几个明确边界。
第一,它依赖本地文件存在。换机器、清理目录、权限受限,都会影响可用性。
第二,它依赖摘要质量。如果摘要漏掉了关键纠正,后续检索就可能复用不完整结论。
第三,它不是实时事实源。记忆里说某个命令以前能跑,不代表今天还能跑。
第四,它不是隐私隔离系统。既然记忆保存在本地文件里,就应该避免把敏感 token、真实 IP、私钥路径、个人隐私写进可复用摘要。
第五,它不是自动决策权。记忆只能影响默认判断,不能覆盖当前用户的新指令。
十、总结
Codex 的记忆功能可以理解为一套本地化、可读、可检索的上下文系统:
memory_summary.md提供快速全局摘要。MEMORY.md提供任务级索引。rollout_summaries/保存可复用经验。rollout_path指向原始 JSONL 会话。- 检索时先摘要、再索引、再原始证据。
它的价值不在于“记住更多”,而在于把历史会话里的有效经验变成下次可执行的约束:哪些路径要优先检查,哪些命令以前验证过,哪些用户偏好不能违背,哪些旧结论必须重新确认。
对 Agent 来说,这比把所有历史塞进上下文更接近一个工程化实现:可索引、可追溯、可修正,也能在必要时回到原始证据。